1. 스케줄링 알고리즘
- CPU 스케줄링은 준비 큐에 있는 프로세스 중 어떤 프로세스에 CPU 코어를 할당할 것인지를 결정
- 여러 가지 다른 CPU 스케줄링 알고리즘이 존재
- 여기서의 스케줄링 알고리즘은 처리 코어가 하나뿐이라고 가정하고 설명
→ 즉 한 번의 하나의 프로세스만 실행할 수 있다는 뜻
1.1. 선입 선처리 스케줄링(FCFS)
- 방식 : CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받는다.
- 가장 간단한 CPU 스케줄링 알고리즘
- 코드 작성과 이해가 쉽다.
- 선입 선처리 정책의 구현은 선입선출(FIFO) 큐로 쉽게 관리 가능
- 프로세스가 준비 큐에 진입하면, 이 프로세스의 프로세스 제어블록(PCB)을 큐의 끝에 연결
- CPU가 가용 상태가 되면, 준비 큐의 앞부분에 있는 프로세스에 할당
- 해당 프로세스(실행 상태의 프로세스)는 준비 큐에서 제거됨
1.1.1. 간트(Gantt) 차트로 보는 FCFS 단점
간트 차트: 프로세스의 시작 시각과 종료 시각을 포함하여 특정 스케줄 기법을 도시하는 막대형 차트- 선입 선처리여서, 평균 대기 시간이 엄청 길어질 수 있다.

- 여기서 버스트 시간은 밀리초 단위
- 프로세스 P1의 대기시간은 0ms, 프로세스 P2는 24ms, 프로세스 P3는 27ms이다.
→ 따라서 평균 대기 시간은 (0+24+27)/3 = 17ms이다. 호위 효과(convoy effect)발생- 호위 효과 : 모든 다른 프로세스들이 하나의 긴 프로세스가 CPU를 양도하기를 기다리는 것
- CPU와 장치 이용률이 저하되는 결과를 낳음
- 해당 경우의 평균 대기 시간은 (0+3+6)/3 = 3ms이다.

평균 대기 시간은 3ms
→ 순서를 바꾼 것만으로 평균대기 시간의 감소가 크다.
→ 선입 선처리 정책은 평균 대기 시간은 일반적으로 최소가 아니다.
- 프로세스 CPU 버스트 시간이 크게 변할 경우에는 평균 대기 시간도 크게 변할 수 있다.
1.1.2. 동적 상황에서 FCFS 스케줄링의 성능
- CPU 중심(CPU-bound) 프로세스와 많은 수의 I/O 중심 프로세스를 가질 때.
- CPU 중심 프로세스가 CPU를 할당받아 점유할 때
- 그동안 다른 모든 프로세스는 I/를 끝내고 준비큐로 이동하여 CPU를 기다림
- 프로세스들이 준비 큐에서 기다리는 동안, I/O 장비는 쉬고 있다.
- I/O 중심의 프로세스들이 CPU를 할당받을 때
- I/O 중심 프로세스들은 매우 짧은 CPU 버스트를 가지고 있기 때문에 CPU 작업이 빨리 끝남
→ 빨리 종료되고 다시 CPU 중심 프로세스가 준비큐로 이동
→ 호위효과 발생
- I/O 중심 프로세스들은 매우 짧은 CPU 버스트를 가지고 있기 때문에 CPU 작업이 빨리 끝남
- CPU 중심 프로세스가 CPU를 할당받아 점유할 때
1.1.3. 선입 선처리 스케줄링 알고리즘 기타 특징
- 선입 선처리 스케줄링 알고리즘은 비선점형
- CPU가 할당되면, 그 프로세스가 종료 혹은 I/O 처리를 요구하여 CPU를 방출할 때까진 CPU 점유
- CPU가 할당되면, 그 프로세스가 종료 혹은 I/O 처리를 요구하여 CPU를 방출할 때까진 CPU 점유
- 선입 선처리 알고리즘은 특히 대화형 시스템에서 문제 발생
- 대화형 시스템에서는 각 프로세스가 규칙적인 간격으로 CPU 몫을 얻는 것이 중요
→ 한 프로세스가 지나치게 오랫동안 CPU를 점유하게 허용하는 것은 손해가 큼
- 대화형 시스템에서는 각 프로세스가 규칙적인 간격으로 CPU 몫을 얻는 것이 중요
1.2. 최단 작업 우선 스케줄링(SJF)
- 방식 : CPU가 이용 가능해지면, 가장 작은 다음 CPU 버스트를 가진 프로세스에 할당
- 각 프로세스에 다음 CPU 버스트 길이를 연관시킴
- 두 프로세스가 동일한 길이의 CPU 버스트라면, FCFS를 적용하여 순위를 정함
- 해당 스케줄링은 프로세스의 전체 길이가 아닌, 다음 CPU 버스트 길이에 의해 스케줄링
→ 최단 다음 CPU 버스트(shortest-next-CPU-burst) 알고리즘이라는 용어가 더 적합
1.2.1. Gantt 차트로 보는 SJF 스케줄링
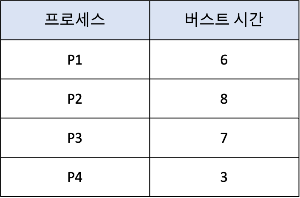

- 버스트 시간이 짧은 순서대로 우선순위를 준다.
- P4의 대기시간 : 0ms, P1의 대기시간 : 3ms, P3의 대기시간 : 9ms, P2의 대기시간 :16ms
→ 평균 대기시간 (0+3+9+16)/4 = 7ms- cf. 선입선출(FCFS)을 사용했다면 평균대기시간은 10.25ms
- cf. 선입선출(FCFS)을 사용했다면 평균대기시간은 10.25ms
- P4의 대기시간 : 0ms, P1의 대기시간 : 3ms, P3의 대기시간 : 9ms, P2의 대기시간 :16ms
- SJF 스케줄링 알고리즘은 주어진 프로세스 집합에 대해 최소 평균 대기시간을 가진다.
→ SJF 스케줄링 알고리즘은 최적임을 증명할 수 있다.
- 짧은 프로세스를 긴 프로세스의 앞으로 이동함으로써, 평균 대기시간을 줄인다.
1.2.2. 다음 CPU 버스트의 길이 예측
- SJF 알고리즘이 최적이긴 하지만, 다음 CPU 버스트의 길이를 미리 알 방법이 없다.
→ CPU 스케줄링 수준에서는 구현할 수 없음 → 그 값을 예측한다. - 방식
- 다음 CPU 버스트가 이전의 비스트와 길이가 비슷하다고 예상
→ 다음 CPU 버스트 길이의 근삿값을 계산해, 가장 짧은 예상 CPU 버스트를 가진 프로세스 선택 - 다음 CPU 버스트는 측정된 이전의 CPU 버스트들의 길이를 지수 평균 한 것으로 예측
지수 평균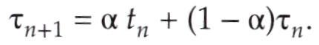
지수 평균 공식
- t_n : n번째 버스트 길이
- 𝛕_n+1 : 다음 CPU 버스트에 대한 예측값
- 0 ≤ 𝛂 ≤ 1
- t_n값은 최근의 정보를 가지며 𝛕_n은 과거의 역사들을 저장한다.
- 매개변수 𝛂는 예측에서 최근의 값과 이전 값의 상대적인 가중치를 제어한다.
- 𝛂 = 0 → 𝛕_n+1 = 𝛕_n → 최근의 역사는 아무 영향이 없다.(현재 조건이 일시적)
- 𝛂 = 1 → 𝛕_n+1 = t_n → 가장 최근의 CPU 버스트만 중요시된다.(역사는 관계 X)
- 𝛂 = 0.5라면 일반적으로, 최근과 과거의 가중치가 같아진다.
- 지수 평균에 대한 공식 확장
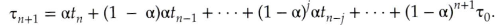
지수 평균 확장
- 𝛕_n을 대치해서 𝛕_n+1에 대한 공식을 확장가능
- 𝛂 (1-𝛂 )가 모두 1보다 작거나 같기 때문에 각 후속 항은 그 전항보다 가중치가 작게 됨
- 다음 CPU 버스트가 이전의 비스트와 길이가 비슷하다고 예상
1.3. SJF 알고리즘 - 최소 잔여 시간 우선 스케줄링이라고도 불림
- SJF 알고리즘은 선점형이거나 비선점형일 수 있다.
- 앞의 프로세스가 실행되는 동안 새로운 프로세스가 준비 큐에 도착하면 선택이 발생
- 새로운 프로세스가 현재 실행되고 있는 프로세스의 남은 시간보다도 짧은 CPU 버스트를 가질 수도 있다.
- 선점형 SJF 알고리즘 ⇒ 현재 실행하는 프로세스를 선점(새로운 프로세스에 CPU 할당)
- 비선점형 SJF 알고리즘 ⇒ 현재 실행하고 있는 프로세스가 자신의 CPU 버스트를 끝내도록 허용
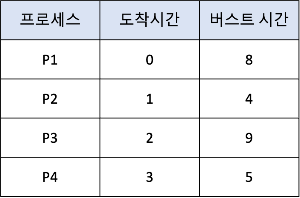

- 프로세스 P1은 큐에 있는 유일한 프로세스이므로 시간 0에 시작
- 프로세스 P2가 시간 1에 도착 → 프로세스 P1의 남은 시간이 7ms, 프로세스 P2가 요구하는 시간은 4ms
→ 따라서 프로세스 P1이 선점되고 프로세스 P2가 스케줄 된다. - 결과적으로 평균대기 시간은 ((10-1)+(1-1)(17-2)+(5-3))/4 = 6.5ms
- cf. 비선점형 SJF 스케줄링 평균 대기시간 : 7.75ms
1.4. 라운드 로빈 스케줄링(RR)
- 방식 : CPU 스케줄러는 준비 큐를 돌면서 한 번에 한 프로세스에 한 번의 시간 할당량 동안 CPU 할당
시간 할당량(time quan-tum): 타임슬라이스라고도 하며, 작은 단위의 시간이라고 정의한다.- 일반적으로 10 ~ 100ms 동안
- 준비큐는 원형 큐로 동작한다.
- 선입 선처리 스케줄링(FCFS)과 비슷하지만 프로세스 사이를 옮겨 다닐 수 있는 선점이 추가된 것
1.4.1. 라운드 로빈 스케줄링 구현
- 준비 큐가 선입선출 큐로 동작하게 만든다.
- 새로운 프로세스들은 준비 큐의 꼬리에 추가된다.
- CPU 스케줄러는 준비큐에서 첫 번째 프로세스를 선택해 1회의 시간 할당량 이후에
인터럽트를 걸도록 타이머 설정한 후, 프로세스를 디스패치한다.
1.4.2. 프로세스에 발생할 수 있는 2가지 경우
- 프로세스의 CPU 버스트가 한 번의 시간 할당량보다 작은 경우
- 프로세스 자신의 CPU를 자발적으로 방출한 뒤,
스케줄러는 그 후 준비 큐에 있는 다음 프로세스로 진행
- 프로세스 자신의 CPU를 자발적으로 방출한 뒤,
- 프로세스의 CPU 버스트가 한 번의 시간 할당량보다 긴 경우
- 타이머가 끝나고 운영체제에 인터럽트가 발생
- 문맥 교환이 일어나고 실행하던 프로세스는 준비 큐의 꼬리에 넣어진다.
- 그 후, CPU 스케줄러는 준비 큐의 다음 프로세스를 선택
1.4.3. 간트 차트로 보는 RR
시간 할당량이 4ms로 가정한다.

- P2와 P3는 4ms를 필요로 하지 않기 때문에, 시간 할당량이 끝나기도 전에 종료한다.
- P1은 (10-4) ms를 기다리고, P2는 4ms, P3는 7ms를 기다린다.
→ 평균 대기 시간 17/3 = 5.6ms - 유일하게 실행 가능한 프로세스가 아니라면 연속적으로 두 번 이상 시간 할당량을 받는 프로세스는 없다.
- 프로세스의 CPU 버스트가 한 번의 시간 할당량을 초과하면, 프로세스는 선점되고 준비큐로 되돌아간다.
→ RR 스케줄링 알고리즘은 선점형이다.
1.4.4. 시간 할당량 공식
- 준비 큐에 n개의 프로세스가 있고 시간 할당량이 q라고 가정
- 각 프로세스는 최대 q 시간 단위의 덩어리로 CPU 시간의 1/n을 얻는다.
- 각 프로세스는 자신의 다음 시간 할당량이 할당될 때까지 (n-1)*q 시간 이상 기다리지 않는다.
1.4.5. RR 알고리즘 기타 특징
- RR 알고리즘의 성능은 시간 할당량의 크기에 많은 영향을 받는다.
- 시간 할당량이 매우 큰 경우 → 선입 선처리 알고리즘과 같아짐
- 시간 할당량이 매우 작은 경우 → 매우 많은 문맥 교환을 야기함.
→ 시간 할당량이 문맥 교환시간과 비교해 더 커야 한다.
- 총 처리 시간(turnaround time)은 시간 할당량의 크기에 좌우된다.
- 한 프로세스의 평균 총 처리 시간은 시간 할당량의 크기가 증가하더라도 반드시 개선되는 것은 아니다.
- 단일 시간 할당량 안에 다음 CPU 버스트를 끝내면 평균 총 처리 시간은 개선됨
1.5. 우선순위 스케줄링
- 방식 : 우선순위가 각 프로세스에 연관되어 있으며, CPU는 가장 높은 우선순위를 가진 프로세스에 할당
- 같은 프로세스들은 선입 선처리(FCFS) 순서로 스케줄 된다.
- 우선순위는 일반적으로 0 ~ 7 또는 0 ~ 4095 같은 일정 범위의 수가 사용된다.
- 최상위 또는 최하위 우선순위에 대한 일반적인 합의는 없다.
- 정의하기 나름
1.5.1. 우선순위 스케줄링 특징
- 우선순위 스케줄링은 선점형이거나 비선점형이 될 수 있다.
- 프로세스가 준비큐에 도착하면, 새로운 프로세스와 현재 실행 중인 프로세스의 우선순위를 비교
- 선점형 우선순위 스케줄링
- 새로운 프로세스가 현재 프로세스의 우선순위보다 높다면 CPU를 선점
- 새로운 프로세스가 현재 프로세스의 우선순위보다 높다면 CPU를 선점
- 비선점형 우선순위 스케줄링
~높다면, 준비 완료 큐의 머리 부분에 새로운 프로세스를 넣는다.
- 선점형 우선순위 스케줄링
- 프로세스가 준비큐에 도착하면, 새로운 프로세스와 현재 실행 중인 프로세스의 우선순위를 비교
1.5.2. 우선순위 스케줄링 주요 문제
무한 봉쇄(indefinite blocking), 기아 상태(starvation)- 우선순위가 낮은 프로세스들이 CPU를 무한히 대기하는 경우
- 실행 준비는 되어 있으나 CPU를 사용하지 못하는 프로세스는 봉쇄된 것으로 간주
- 높은 우선수위의 프로세스들이 계속 들어와서 낮은 우선순위의 프로세스들이 CPU를 못 얻는 것
- 문제들로 인해 컴퓨터 시스템이 크래시 하여 우선순위가 낮은 프로세스들을 잃어버린다.
- 해결법
노화(aging): 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시킨다.- 라운드 로빈과 우선순위 스케줄링을 결합하는 방법
- 시스템이 우선순위가 가장 높은 프로세스를 실행하고,
우선순위가 같은 프로세스들은 라운드 로빈 스케줄링(RR)을 사용하는 스케줄 하는 방식
- 시스템이 우선순위가 가장 높은 프로세스를 실행하고,
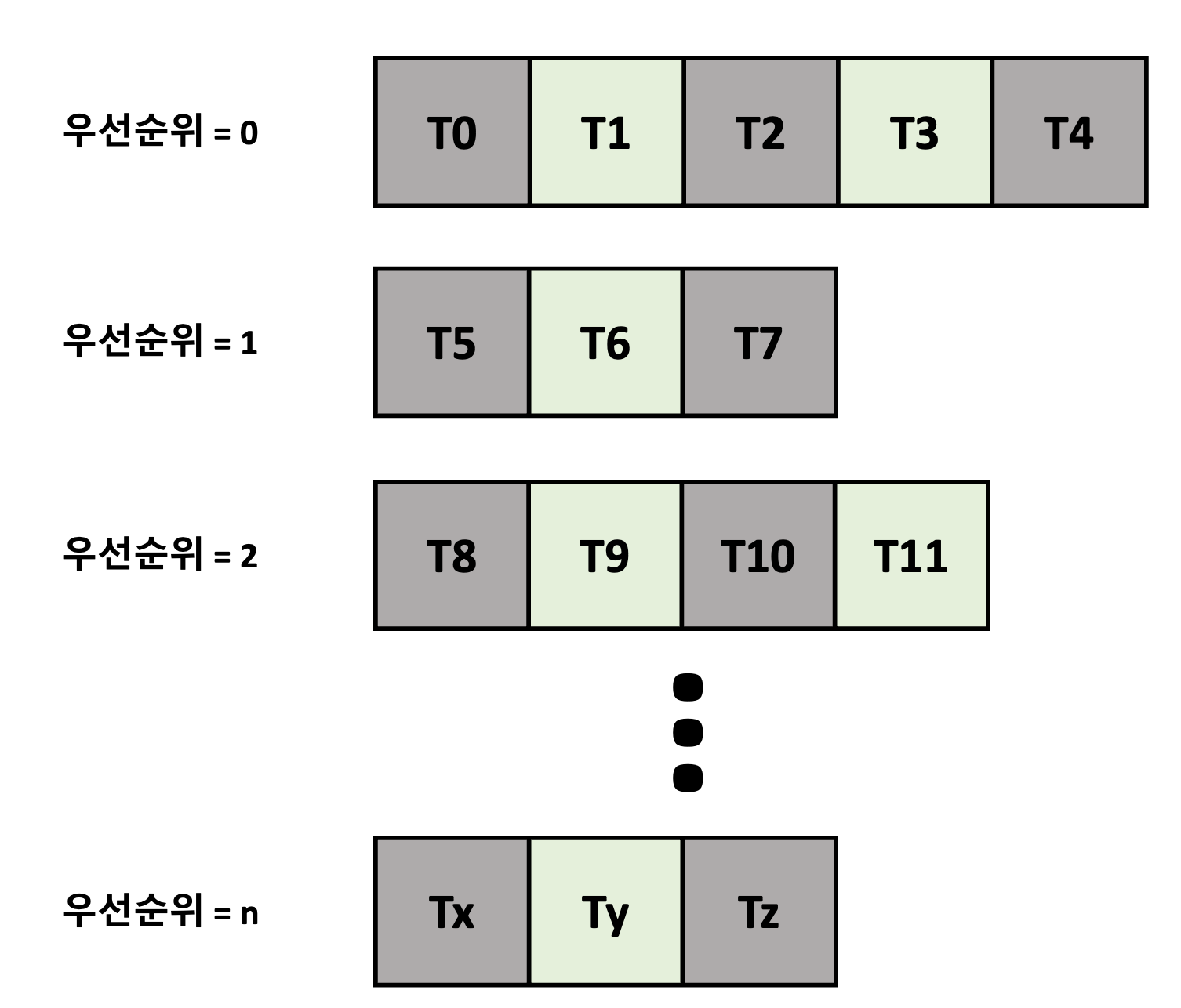
1.5.3. 다단계 큐 스케줄링
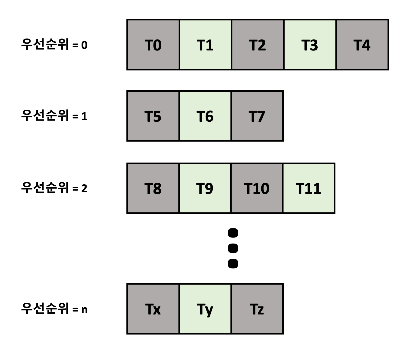
- 우선순위마다 별도의 큐를 갖는 것이 더 나을 때도 있다.
→ 우선순위 스케줄링은 우선순위가 가장 높은 큐에서 프로세스를 스케줄 한다. - 우선순위 스케줄링이 라운드 로빈과 결합한 경우에도 효과적
- 가장 일반적인 형태에서 우선순위가 각 프로세스에 정적으로 할당
- 프로세스는 실행시간 동안 동일한 큐에 남아있다.
- 가장 일반적인 형태에서 우선순위가 각 프로세스에 정적으로 할당
1.5.4. 프로세스 유형에 따라 개별 큐에 분할
- 프로세스 유형에 따라 프로세스를 여러 개의 개별 큐로 분할하기 위해 다단계 스케줄링 알고리즘 사용
- 흔히 포그라운드(대화형) 프로세스와 백그라운드(배치) 프로세스를 구분
- 두 유형의 프로세스는 응답 시간 요구 사항이 다르므로 스케줄링 요구 사항이 다를 수 있음
- 포그라운드 프로세스는 백그라운드 프로세스보다 우선순위를 가질 수 있다.
- 포그라운드 및 백그라운드 프로세스에 별도의 큐가 사용될 수 있음
- 각 큐에는 자체 스케줄링 알고리즘이 있을 수 있다.
- 각 큐에는 자체 스케줄링 알고리즘이 있을 수 있다.
- 흔히 포그라운드(대화형) 프로세스와 백그라운드(배치) 프로세스를 구분
- 큐와 큐 사이에 스케줄링도 반드시 존재해야 함 → 고정 우선순위의 선점형 스케줄링으로 구현
1.6. 다단계 피드백 큐 스케줄링
- 프로세스가 큐들 사이에 이동하는 것을 허용한다.
- cf. 다단계 큐 스케줄링 알고리즘은 시스템 진입 시 영구적으로 하나의 큐에 할당됨
→ 해당 방식은 융통성이 적음
- cf. 다단계 큐 스케줄링 알고리즘은 시스템 진입 시 영구적으로 하나의 큐에 할당됨
- 방법
- 프로세스들을 CPU 버스트 성격에 따라서 구분
- 어떤 프로세스가 CPU 시간을 너무 많이 사용하면, 낮은 우선순위의 큐로 이동됨
- 해당 방법에서는 I/O 중심의 프로세스와 대화형 프로세스들을 높은 우선순위의 큐에 넣는다.
← 통상 짧은 CPU 버스트를 갖기 때문에 - 마찬가지로 낮은 우선순위의 큐에 오래 대기하는 프로세스는 높은 우선순위 큐로 이동한다.
→ 이러한 방식으로 기아 상태를 예방한다.
- 해당 방법에서는 I/O 중심의 프로세스와 대화형 프로세스들을 높은 우선순위의 큐에 넣는다.
1.6.1. 다단계 피드백 큐 특징
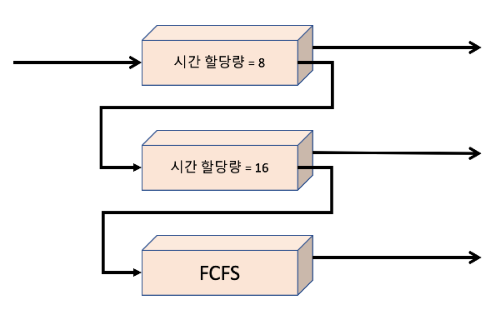
- CPU 버스트가 8ms 이하인 모든 프로세스에 최고의 우선순위를 부여
→ 프로세스가 빨리 CPU를 할당받아서, CPU 버스트를 빨리 끝내고 다음의 I/O 버스트로 간다.
- 8ms ~ 24ms 가 필요한 프로세스들도 우선순위가 낮지만 서비스를 빠르게 받는다.
- 긴 프로세스는 자동으로 큐 2로 가게 되며, 큐 0과 큐 1이 사용하지 않는
CPU 주기에 선입 선처리 방식으로 처리됨
- 해당 스케줄링 방식이 가장 일반적인 CPU 스케줄링 알고리즘임
- 해당 알고리즘은 설계 중인 특정 시스템에 부합하도록 구성 가능함.
- 하지만, 매개변수의 값을 선정하는 특정 방법이 필요함 → 가장 복잡한 알고리즘이기도 함
1.6.2. 다단계 피드백 큐 스케줄러 관련 매개변수
일반적으로 다음의 매개변수에 의해 정의됨
- 큐의 개수
- 각 큐를 위한 스케줄링 알고리즘
- 한 프로세스를 높은 우선순위 큐로 올려주는 시기를 결정하는 방법
- 한 프로세스를 낮은 우선순위 큐로 강등시키는 시기를 결정하는 방법
- 프로세스에 서비스가 필요할 때 들어갈 큐를 결정하는 방법
2. 스레드 스케줄링(Thread Scheduling)
2.1. 경쟁 범위
- 사용자 수준과 커널 수준 스레드의 차이
- 그들이 어떻게 스케줄 되느냐의 차이
- 사용자 수준 스레드 → LWP 상에서 스케줄 됨
→ 동일한 프로세스에 속한 스레드들 사이에서 CPU를 경쟁 ⇒프로세스-경쟁-범위(PCS)
- 스레드 라이브러리가 사용자 수준 스레드를 가용한 LWP 상에서 스케줄 한다고 말하는 경우
→ 스레드가 실제로 CPU상에서 실행 중이라는 것을 의미하지 않는다.- 실제로 CPU상에서 실행되기 위해서는 운영체제가 LWP의 커널 스레드를
물리적인 CPU 코어로 스케줄 하는 것을 필요로 함
- 실제로 CPU상에서 실행되기 위해서는 운영체제가 LWP의 커널 스레드를
2.1.1. 시스템 경쟁범위
시스템-경쟁범위(SCS): CPU상에 어느 커널 스레드를 스케줄 할 것인지 결정하기 위해 사용하는 것- SCS 스케줄링에서의 CPU에 대한 경쟁은 시스템상의 모든 스레드 사이에서 발생한다.
- SCS 스케줄링에서의 CPU에 대한 경쟁은 시스템상의 모든 스레드 사이에서 발생한다.
- PCS는 우선순위에 따라 행해진다. → 스케줄러는 가장 높은 우선순위를 가진 프로세스를 선택
- 사용자 수준 스레드의 우선순위는 프로그래머에 의해 지정되고
스레드 라이브러리에 의해 조정되지 않는다. - 몇몇 스레드 라이브러리는 프로그래머가 스레드의 우선순위를 변경하는 것을 허용한다.
- 사용자 수준 스레드의 우선순위는 프로그래머에 의해 지정되고
- PCS는 통상 더 높은 우선순위의 스레드를 위해 현재 실행 중인 스레드를 선점
- 같은 우선순위의 스레드들 사이에는 타임 슬라이스에 대한 보장은 없다.