1. 알고리즘의 평가
- 특정 시스템을 위한 CPU 스케줄링 알고리즘은 어떻게 선택하는가?
1.1. 알고리즘을 선택하는 데 사용할 기준을 정의
- 알고리즘을 선택하기 위해 매개변수들의 상대적인 중요성을 반드시 정의해야 한다.
- 기준은 종종 CPU 이용률, 응답시간 또는 처리량에 의해 정의된다.
- 기준은 종종 CPU 이용률, 응답시간 또는 처리량에 의해 정의된다.
- 기준은 아래와 같은 대책을 포함할 수도 있음
- 최대 응답 시간은 300ms라는 제약 조건에서 CPU 이용률을 극대화한다.
- 총 처리 시간이 전체 실행 시간에 평균적으로 선형 비례가 되도록 처리량을 극대화한다.
- 선택 기준의 정의되면, 여러 가지 알고리즘들을 평가하기를 원한다.
→ 아래에서 사용할 수 있는 여러 평가 방법들을 기술
2. 결정론적 모델링
분석적 평가(analytic evaluation)- 평가 방법의 중요한 부류 중 하나
- 주어진 작업 부하에 대한 알고리즘의 성능을 평가하는 공식이나
값을 생성하기 위해 주어진 알고리즘과 시스템 작업 부하를 이용한다.
- 결정론적 모델링(deterministic modeling) ← 분석적 평가의 한 가지 유형
- 사전에 정의된 특정 작업 부하를 받아들여 그 작업부하에 대한 각 알고리즘의 성능을 정의
2.1. 결정론적 모델링 사용 예시

- 해당 프로세스 집합에 대해 선입 선처리, SJF, 라운드 로빈(시간 할당량 = 10ms) 스케줄링 고려
→ 어떤 알고리즘의 평균 대기 시간이 가장 짧은가?- 선입 선처리 : 28ms
- 비선점 SJF : 13ms
- 라운드 로빈 : 23ms
- 결과
- SJF 정책의 평균 대기 시간이 선입 선처리 스케줄링보다 절반정도 작다.
- 라운드 로빈 알고리즘은 중간 정도이다.
2.2. 결정론적 모델링 특징
- 결정론적 모델링은 단순하고 빠르다. → 알고리즘을 비교할 수 있도록 정확한 값을 제공
- But, 입력으로 정확한 숫자를 요구하고, 응답도 비교한 것들의 경우에만 적용
- But, 입력으로 정확한 숫자를 요구하고, 응답도 비교한 것들의 경우에만 적용
- 결정론적 모델링은 스케줄링 알고리즘을 설명하고 예를 제공하는 데 사용
- 동일한 프로그램을 반복 실행하고, 프로그램의 처리 요구 사항을 정확하게 측정가능할 경우 사용
3. 큐잉 모델(Queueing Models)
3.1. CPU와 I/O 버스트
- 결정론적 모델링을 사용할 수 있는 프로세스들의 정적인 집합은 거의 없다.
→ 결정할 수 있는 것은 CPU와 I/O 버스트의 분포 - CPU와 I/O버스트의 분포는 측정 가능하고, 근삿값을 계산하거나 추정할 수 있다.
→ 특정 CPU 버스트의 확률을 기술하는 수학적인 공식을 얻을 수 있다.
- 이런 분포는 보통 지수적이며 평균으로 기술됨
- 이들 분포로부터 알고리즘 대부분에 대한 평균 처리량, 이용률을 대기 시간 등을 계산할 수 있다.
3.2. 큐잉 네트워크 분석
- 컴퓨터 시스템은 서버들의 네트워크로 기술
- 각 서버는 대기 프로세스들의 큐를 지님
- CPU → 준비 큐를 가진 서버
- I/O 시스템 → 장치 큐를 가진 서버
- 각 서버는 대기 프로세스들의 큐를 지님
- 서버에서의 도착률과 서비스율을 알 수 있다.
→ 이용률, 평균 큐 길이, 평균 대기 시간 등을 계산할 수 있다.
→ 이러한 영역에 관한 연구를 큐잉 네트워크 분석(queueing network analysis)라고 한다.
3.3. Little’s formula
- 공식
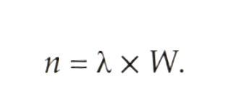
Little's formula 공식 - n = 평균 큐 길이(서비스를 받는 중인 프로세스는 제외)
- W = 큐에서의 평균 대기시간
- 𝜆 = 새로운 프로세스들이 큐에 도착하는 평균 도착률( Ex : 1초에 3개의 프로세스)
- 해당 공식은 어떠한 스케줄링 알고리즘이나 어떠한 도착 분포에서도 성립하기 때문에 유용
- 프로세스가 대기하는 시간 W 동안에 𝜆 * W개의 새로운 프로세스들이 큐에 도착
- 시스템이 안정된 상태라면 큐를 떠나는 프로세스와 도착하는 프로세스의 수가 같아야 한다.
- 시스템이 안정된 상태라면 큐를 떠나는 프로세스와 도착하는 프로세스의 수가 같아야 한다.
- 3개의 변수 중 2개의 변수를 알고 있다면 나머지 하나를 계산할 수 있다.
3.4. 큐잉 분석 한계
- 분석할 수 있는 알고리즘과 분포의 부류가 상당히 제한되어 있다.
- 복잡한 알고리즘이나 분포와 관련된 수학적 분석이 어려움
→ 도착과 서비스 분포들이 대개 비현실적이지만, 수학적으로 분석하기 쉬운 방법으로 정의
- 복잡한 알고리즘이나 분포와 관련된 수학적 분석이 어려움
- 정확하지 않을 수 있는 다수의 독립된 가정을 하는 것이 필요로 한다.
→ 큐잉 모델들은 실제 시스템의 근사치이며 연산된 결과의 정확성에는 의심의 여지가 남아있음
4. 모의실험(Simulation)
- 모의실험을 하는 것은 컴퓨터 시스템의 모델을 프로그래밍하는 것을 포함한다.
- 모의실험을 실행하면서 알고리즘의 성능을 나타내는 통계들을 수집하고 인쇄한다.
4.1. 모의실험 구동하기 위한 자료 생성 방법 - 난수 발생기
난수 발생기(random number generator)- 확률 분포에 따라 프로세스, CPU 버스트 시간, 도착, 출발 등을 생성하기 위해 프로그램됨
- 분포는 수학적으로 [균등, 지수, 푸아송], 또는 경험적으로 정의될 수 있다.
- 경험적으로 분포를 정의하려면, 연구 대상이 되는 실제 시스템에 대한 측정이 행해짐
→ 그 결과는 실제 시스템에서 이벤트들의 실제 분포를 정의
- 경험적으로 분포를 정의하려면, 연구 대상이 되는 실제 시스템에 대한 측정이 행해짐
- 만들어진 분포는 모의실험을 구동하는 데 사용
- 한계점 : 이 방식은 실제 시스템에서 연속적인 이벤트 사이의 관계 때문에 부정확할 수도 있음
- 빈도수 분포는 단지 각 이벤트가 얼마나 많이 발생하는가를 의미한다.
→ 이들의 생성 순서에 대해서는 아무런 정보도 제공하지 않는다.
- 빈도수 분포는 단지 각 이벤트가 얼마나 많이 발생하는가를 의미한다.
- 해결법 : 추적 파일을 사용한다.
- 실제 이벤트들의 순서를 기록하여 추적 파일을 생성한다.
→ 이 순서를 모의실험을 실행하는 데 사용할 수 있다. - 추적 파일은 실제 입력들과 정확히 동일한 입력으로 2개의 알고리즘을 비교하는 좋은 방법
→ 해당 방법으로 입력에 대한 정확한 결과를 생성할 수 있음
- 실제 이벤트들의 순서를 기록하여 추적 파일을 생성한다.
4.2. 모의실험 유의점
- 모의실험은 컴퓨터를 오래 사용하기 때문에 매우 큰 비용이 소모될 수 있음
- 모의실험이 상세할수록 더 정확한 결과를 얻을 수 있지만 컴퓨터 사용시간이 더 필요함
- 추적 파일은 대량의 저장공간을 요구할 수 있다.
- 모의실험기의 설계, 코딩, 오류 수정은 매우 중요한 작업이 될 수 있다.
5. 구현(Implementation)
- 실제 운영 환경하에서의 평가를 위해 실제 코드로 작성해 운영체제에 넣고 실행해 보는 방식
- 해당 방식은 비용이 많이 든다.
- 비용이 드는 곳
- 알고리즘 코드 작성 비용
- 작성한 코드를 지원하기 위해 운영체제 코드와 그에 따른 자료구조를 변경하는 비용
- 가상 머신에서 변경 사항을 테스트하는 비용(전용 하드웨어가 아닌 이상)
- 비용이 드는 곳
- 회귀 테스트를 통해 변경사항이 더 나빠지지 않았으며, 버그가 발생하지 않았음을 확인할 수 있다.
5.1. 구현 방식의 어려움 - 사용되는 환경의 변화
- 환경은 스케줄러가 보이는 성능의 결과에 따라서 변화할 수도 있다.
- 짧은 프로세스에 우선순위를 주면,
사용자들은 큰 프로세스를 작은 프로세스들의 집합으로 나눌 것이다. - 비대화형 보다 대화형 프로세스에 우선순위를 주면,
사용자들은 컴퓨터를 대화형으로 사용할 것이다.
- 짧은 프로세스에 우선순위를 주면,
- 해당 문제의 해결법
- 완전한 조치의 집합을 캡슐화한 도구 또는 스크립트를 사용하고,
해당 도구를 반복적으로 사용하며, 결과를 측정하는 동안 도구를 사용하여 해결한다.
- 완전한 조치의 집합을 캡슐화한 도구 또는 스크립트를 사용하고,
5.2. 융통성 있는 스케줄링 알고리즘
- 시스템 관리자 또는 사용자에 의해 알고리즘이 특정 응용이나 응용 집합에 맞도록 조정될 수 있게 한다.
- 프로세스나 스레드의 우선순위를 변경하는 API를 사용하는 것
- 단점 : 종종 성능조정이 더 일반적인 상황에서는 개선된 성능을 낳지 않을 수도 있다.