IPv6 개발 배경
- 1990년대 초에 IETF는 IPv4 프로토콜의 다음 버전을 개발하기 시작
- IPv4 주소 공간이 고갈되기까지는 아직 상당히 시간이 남았지만,
광범위하게 새로운 기술을 구축하기에는 상당히 시간이 필요하기 때문에 이때 시작됨
- IPv4 주소 공간이 고갈되기까지는 아직 상당히 시간이 남았지만,
- IPv6 개발의 주된 동기
→ 32비트 IPv4 주소 공간이 인터넷에 접속하는 서브넷과 노드들로 인해 빠른 속도로 고갈 진행 중
→ 큰 IP 주소 공간의 필요성을 인식하여 새로운 IP 프로토콜인 IPv6가 개발됨 - IPv6 개발자들은 IPv4의 축적된 운용 경험에 근거하여 IPv4의 다른 면을 확장하고 축소하였음
IPv6 데이터그램 포맷
IPv6에 도입된 중요한 변화
1. 확장된 주소 기능
- IPv6는 IP 주소 크기를 32비트에서 128비트로 확장 → IP 주소가 고갈되는 일은 발생 X
- IPv6는 새로운 주소 형태인
애니캐스트 주소(anycast address)를 도입함- 애니캐스트 주소로 명시된 데이터그램은 호스트 그룹의 어떤 이이게든 전달될 수 있음
- 예시 : 주어진 문서를 포함한 수많은 미러 사이트 중 가장 근접한 HTTP GET을 보내는 데 사용 가능
- 예시 : 주어진 문서를 포함한 수많은 미러 사이트 중 가장 근접한 HTTP GET을 보내는 데 사용 가능
- 기존에 있던 유니캐스트, 멀티캐스트 주소도 그대로 사용
- 애니캐스트 주소로 명시된 데이터그램은 호스트 그룹의 어떤 이이게든 전달될 수 있음
2. 간소화된 40바이트 헤더
- IPv4의 많은 필드가 생략되거나 옵션으로 남겨짐
- 40바이트의 고정 길이 헤더는 라우터가 IP 데이터그램을 더 빨리 처리하게 해 줌
- 새로운 옵션 인코딩은 유연한 옵션 처리를 가능하게 한다.
3. 흐름 레이블링
- IPv6는 정의하기 어려운 흐름(flow, 플로우)을 가지고 있다.
- 특별한 처리를 요청하는 송신자에 대해 특정 흐름에 속하는 패킷 레이블링을 가능하게 한다.
- 특별한 처리 요청 : 비 디폴트 품질 서비스, 실시간 서비스 등
- RFC 2460에서 정의한 설명
- IPv6 설계자는 언젠가 필요할 흐름 차별화를 예견했다.
- 흐름 차별화 예시
- 오디오/비디오 전송 → 흐름으로 처리
- 파일 전송, 전자 메일 같은 예전의 애플리케이션 → 흐름으로 처리되지 않음
- 높은 사용자 우선순위를 가지고 전달된 트래픽 또한 흐름으로 처리될 수 있음
- 흐름 차별화 예시
IPv6 데이터그램에 존재하는 필드
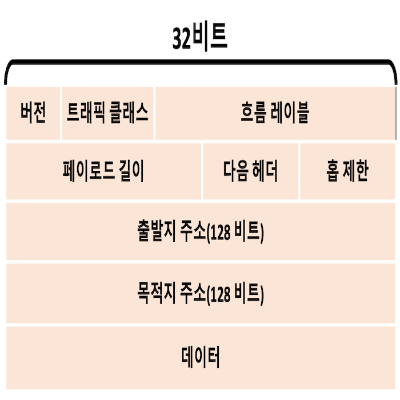
버전: 4비트 필드로, IP 버전 번호를 인식한다.- IPv6의 해당 필드값은 ‘6’이다.
- 단순히 이 필드를 ‘4’로 설정한다고 IPv4 데이터그램을 만들 수 있는 것은 아님
트래픽 클래스: 8비트 필드로, 특정 애플리케이션 데이터그램에 우선순위를 부여하는 데 사용- IPv4의 TOS 필드와 비슷한 의미로 만들어진 필드
- 예시 : 흐름 내의 SMTP 이메일보다 VoIP에게 우선순위가 있어야 함
흐름 레이블: 20비트 필드로, 데이터그램의 흐름을 인식하는 데 사용페이로드 길이: 16비트 필드로, IPv6 데이터그램에서 패킷 헤더 뒤에 나오는 바이트 길이이다.- 고정 길이 40바이트 패킷 헤더 뒤에 오는 부호 없는 정수(unsigned integer)이다.
- 고정 길이 40바이트 패킷 헤더 뒤에 오는 부호 없는 정수(unsigned integer)이다.
다음 헤더: 해당 필드는 데이터그램의 내용(데이터 필드)이 전달될 프로토콜을 구분한다.- TCP나 UDP를 구분한다.
- 이 필드는 IPv4의 헤더에 있는 프로토콜 필드와 같다.
홉 제한: 홉 제한 수가 0보다 작아지면 라우터는 데이터그램을 버려야 한다.- 이 필드의 내용은 라우터가 데이터그램을 전달할 때마다 1씩 감소
- 이 필드의 내용은 라우터가 데이터그램을 전달할 때마다 1씩 감소
출발지와 목적지 주소: IPv6 128비트 주소의 다양한 형태는 RFC 4291에 있음데이터: IPv6 데이터그램의 페이로드 부분- 데이터그램이 목적지에 도착하면 IP 데이터그램에서 페이로드를 제거한 후,
다음 헤더 필드에 명시한 프로토콜에 전달
- 데이터그램이 목적지에 도착하면 IP 데이터그램에서 페이로드를 제거한 후,
IPv6에서 없앤 필드(IPv4에만 존재하는 필드)
단편화/재결합- IPv6에서 단편화와 재결합을 출발지와 목적지만이 수행한다.
- 라우터가 받은 IPv6 데이터그램이 너무 커서 출력 링크로 전달할 수 없는 경우
- 데이터그램을 폐기하고 패킷이 너무 크다(Packet Too Big)라는 ICMP 오류 메시지를 송신자 전송
- 송신자는 데이터를 IP 데이터그램 크기를 줄여서 다시 보냄
- 단편화와 재결합은 시간이 걸리므로 라우터에서 이 기능을 삭제
→ 대신 종단 시스템이 하게 하여 네트워크 IP 전달 속도가 증가
헤더 체크섬- 트랜스포트 계층 프로토콜과 데이터 링크 프로토콜은 체크섬을 수행
→ 네트워크 계층의 체크섬 기능은 중복되는 것이므로 생략해도 될 것이라 생각 - IP 패킷의 빠른 처리에 주요 관점을 둠
- IPv4 헤더는 TTL 필드를 포함하여 IPv4 헤더 체크섬을 모든 라우터마다 수행
→ 비용이 많이 드는 과정이었음
- 트랜스포트 계층 프로토콜과 데이터 링크 프로토콜은 체크섬을 수행
옵션- 옵션 필드는 더 이상 표준 IP 헤더 필드가 아님
→ 하지만 완전히 사라진 것은 아니고, 대신 옵션 필드는 IPv6 헤더에서 다음 헤더 중 하나가 될 수 있음 - TCP나 UDP 프로토콜 헤더가 IP 패킷에서 다음 헤더가 될 수 있는 것처럼 옵션 필드 역시 그럴 수 있다.
- 옵션 필드가 제거되었기 때문에 표준에서는 고정 길이의 40바이트 IP 헤더를 갖게 됨
- 옵션 필드는 더 이상 표준 IP 헤더 필드가 아님
IPv4에서 IPv6로의 전환
- IPv4 데이터그램을 IPv6로 구축된 시스템으로 처리하는 것 → 가능
- IPv6 데이터그램을 IPv4로 구축된 시스템으로 처리하는 것 → 불가능
해결법 1 - 플래그 데이(flag day) 선언
- 모든 인터넷 장비를 끄고 IPv4에서 IPv6로 업그레이드하는 시간과 날짜를 정하는 것
- 수억 개의 장비가 관련된 플래그 데이는 오늘날에 사실상 불가능함
해결법 2 - 터널링(tunneling)[RFC 4213]
터널링의 기본 개념

- 가정
- 2개의 IPv6 노드가 IPv6 데이터그램을 사용해서 동작
- 이 2개의 노드는 IPv4 라우터를 통해 연결되어 있다.
터널(tunnel): 두 IPv6 사이에 있는 IPv4 라우터들을 터널이라고 함
터널링 과정

- 터널의 송신 측에 있는 IPv6 노드(B)는 IPv6 데이터그램을 받고,
IPv4 데이터그램의 데이터(페이로드) 필드에 이것을 넣음 - 이 IPv4 데이터그램에 목적지 주소를 터널의 수신 측에 IPv6 노드(E)로 적어,
터널의 첫 번째 노드(C)로 보낸다. - 터널 내부에 있는 IPv4 라우터는 IPv4 데이터그램이 IPv6 데이터그램을 갖고 있다는 사실을 모른 채,
다른 데이터그램을 처리하는 방식으로 이 IPv4 데이터그램을 처리한다. - 터널 수신 측에 있는 IPv6 노드는 IPv4 데이터그램을 받는다.
- IPv6 노드가 IPv4 데이터그램을 받는 이유 → IPv4 데이터그램의 목적지이기 때문
- IPv6 노드가 IPv4 데이터그램을 받는 이유 → IPv4 데이터그램의 목적지이기 때문
- 이후, 이 IPv4 데이터그램이 실제 IPv6 데이터그램임을 결정
- IPv6 데이터그램임을 결정할 수 있는 근거
- IPv4 데이터그램 프로토콜 번호 필드가 41 → IPv4 페이로드는 IPv6 데이터그램임을 알 수 있음
- IPv4 데이터그램 프로토콜 번호 필드가 41 → IPv4 페이로드는 IPv6 데이터그램임을 알 수 있음
- IPv6 데이터그램임을 결정할 수 있는 근거
- 이 노드는 IPv6 데이터그램으로 만든 다음에 IPv6 데이터그램을 IPv6 노드로 보낸다.
IPv6의 최근 동향
- 미국 정부의 2단계 도메인 중 1/3 이상이 IPv6를 사용할 수 있다고 보고
- 클라이언트 측에서 구글은 구글 서비스에 접속하는 클라이언트 중 약 25%가 IPv6를 사용한다고 보고
- IPv6 채택이 가속화되고 있음